gutenberg地址:http://www.gutenberg.org/
前记:对象的作业是翻译还没有被翻译过的英文科幻小说。百度搜索无望,借助了伟大的python和伟大的gutenberg下载了1000多篇英文科幻小说。下一步希望能通过程序判断这些文章是否被翻译过。
学习到的内容:
1. 在寻找提取链接的规律时,需要多思考。最初选择直接提取链接,遇到很多问题。后来选择直接提取编号,就变得容易很多。
2. 正则表达式的使用还需加强。
3. 注意 try… except… 的使用。
python"># -*- coding: utf-8 -*-
"""
Created on Wed Feb 15 12:04:26 2017
@author: Wayne
"""
import urllib2, re
url = "http://www.gutenberg.org/wiki/Science_Fiction_(Bookshelf)#B"
# gutenberg上科幻小说类目地址
content = urllib2.urlopen(url).read()
# 读取类目网页内的信息
relink = 'title="ebook:(\d{1,10})">'
# 设置正则表达式
links = re.findall(relink, content)
# 通过正则表达式提取网页内的书籍编号,生成列表links
x = 0
# 计数符号,用于书籍命名和程序输出
book_url_list = []
# 初始化列表,用于存放每本书的链接
for link in links:
# 遍历书籍编号
link = 'http://www.gutenberg.org/ebooks/'+link
# 将书籍编号和地址头合并为有效链接
book_url_list.append(link)
# 将有效链接追加到书籍链接列表中
for i in book_url_list:
# 遍历链接列表
x = x+1
# 计数
try:
# 正常运行
html_doc = urllib2.urlopen(i).read()
# 读取书籍链接内容
f_url_h = html_doc.find('<a href="//')
f_url_t = html_doc.find('" type="text/html;')
f_url_a = "http://"+html_doc[f_url_h+11 : f_url_t]
# 得到书籍内容页面的链接
a = urllib2.urlopen(f_url_a).read()
# 读取书籍内容
f_name_h = html_doc.find('<h1 itemprop="name">')
f_name_t = html_doc.find('</h1>')
b = html_doc[f_name_h+20 : f_name_t]
# 得到书名
fout = open('SF%d%s.html' %(x,b), 'w')
# 建立并打开以书名命名的html文件
fout.write(a)
# 将书籍内容写入文件
fout.close()
# 关闭文件
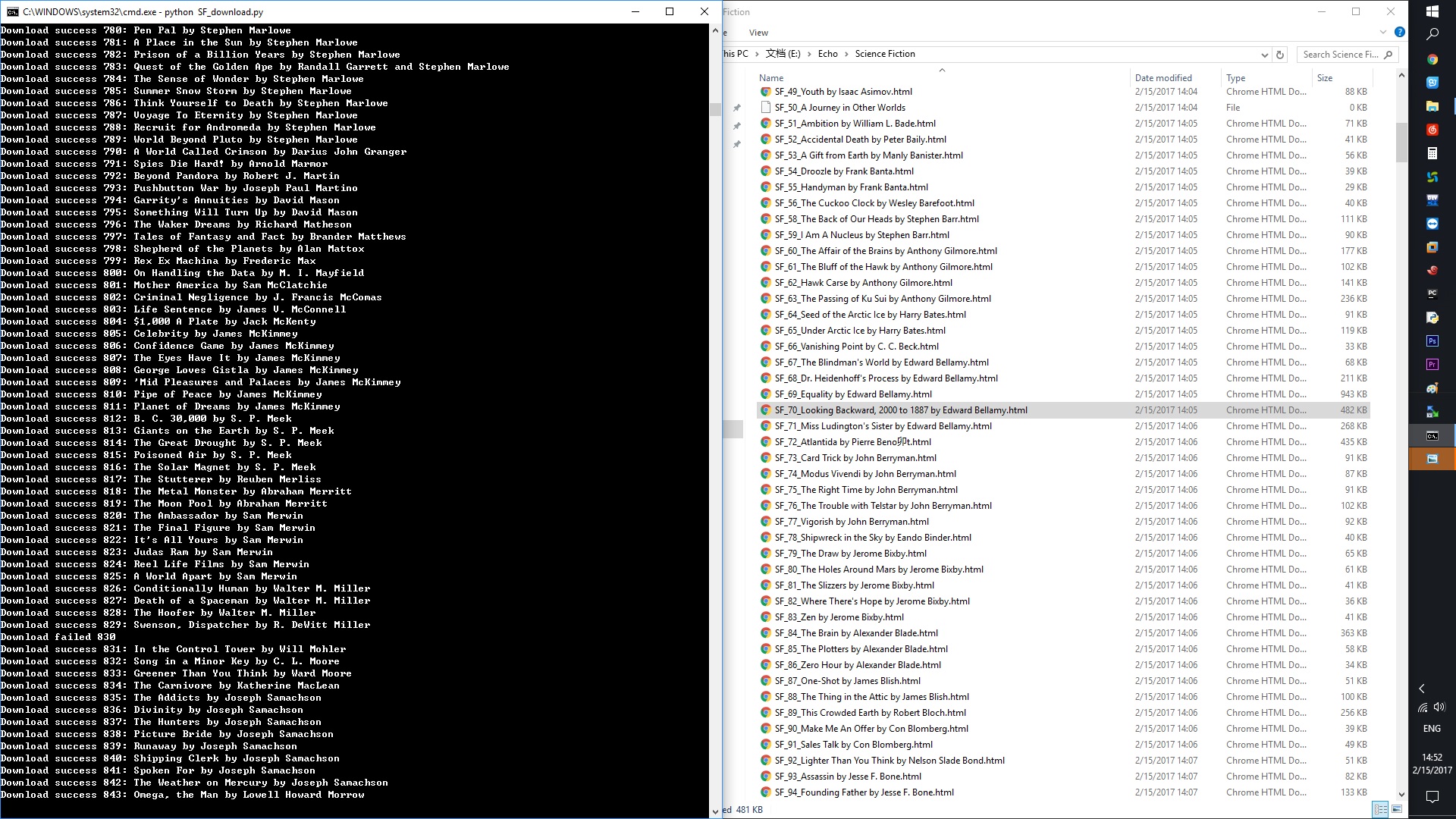
print "Download success %d: %s" %(x, b)
# 打印下载成功信息:包含编号和书名
except:
# 若发生错误,则直接略过,进行下一个链接循环
print "Download failed %d" %x
# 打印失败信息和编号
continue